


탄소 친화적 딥러닝 워크로드를 위한 시공간 이동 및 GPU 최적화 SW
팀 명 (팀원) : Carbon Watch (박정현, 김대로)
1. 프로젝트 소개
 ##### 그림. 1 프로젝트 수행 배경 및 관련 연구 개요
##### 그림. 1 프로젝트 수행 배경 및 관련 연구 개요
배경
LLMs과 같은 대규모 딥러닝으로 워크로드로부터 발생하는 방대한 탄소 배출량의 절감이 시급함:
- 대규모 AI는 방대한 전력을 소비하며, AI 학습을 위한 신규 장비 구매는 많은 비용 부담이 존재함.
- 전세계적으로 분포된 클라우드는 지구 전체의 온실가스 증가에 1% 기여.
전력 생산자원과 날씨 및 시간에 따라 발생되는 탄소 강도(Carbon Intensity)의 차이는 중요함:
- 24시 평균 탄소 강도* 비교 시 한국-375g/kWh, 프랑스-75g/kWh, 독일-514g/kWh 차이 발생
*탄소 강도: 1kWh의 전기를 생산하기 위해 방출되는 CO2의 양을 측정한 것이며, 전력 생산자원에 따라 차이가 발생함.
기존 연구
대부분의 마이그레이션 연구는 비용 감소, 전력 소비량 감소, 성능을 위해 진행됨:
- 비용 감소: 비용과 지연시간 간의 균형을 위한 강화학습 기반의 마이그레이션 방법 -전력 소비량 감소: 전기 가격 변동성과 함께 최적화 기법을 적용해 마이그레이션 결정 여부 채택
- 네트워크 대역폭: 유휴 네트워크 대역폭을 활용한 알고리즘
- 지연시간: 강화학습 기반의 지연시간 단축 알고리즘
- 모바일 기기의 하드웨어 성능 제약:복잡한 계산이 필요한 작업을 클라우드 서버로 이동하는 방법
-
최근 탄소인지 작업 마이그레이션 연구가 일부 있으나, 딥러닝 학습의 재현성 유지는 어려움:
- 작업 분배 및 냉각 장비의 공급 온도에 따라 최적의 지역에 마이그레이션 결정하는 방법
- Service Level Agreement 기반의 마이그레이션과 시공간적 탄소 강도를 이용한 방법이 존재
2. 분산된 클라우드에서 딥러닝 워크로드의 탄소 인지 이동 및 전력 최적화 기술
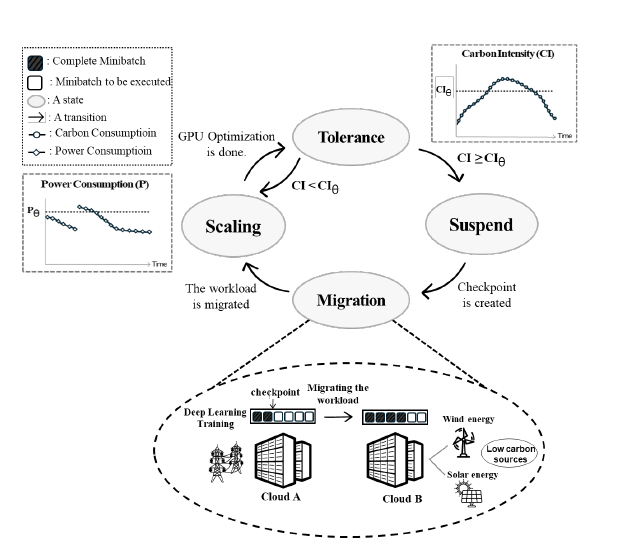
##### 그림. 2 제안하는 기술의 개념도
CAFTM은 스케일링, 관용, 중지, 마이그레이션의 네 가지 절차적 상태를 통해 작동한다.
스케일링 상태에서 관용 상태로의 전환이 반복적으로 작동하여 탄소 강도가 임계점 이하로 유지되는 동시에 GPU 전력 소비를 최적화 한다.
탄소 집약도가 임계점을 초과하면 중지 상태로 전환하고, 탄소 강도가 더 낮은 클라우드 위치로 마이그레이션하는 체크포인트를 시작한다. 해당 체크포인트는 마이그레이션 후 작업 재개를 용이하게 하며, 스케일링 상태로 재가동 된다.
3. 사용된 기술
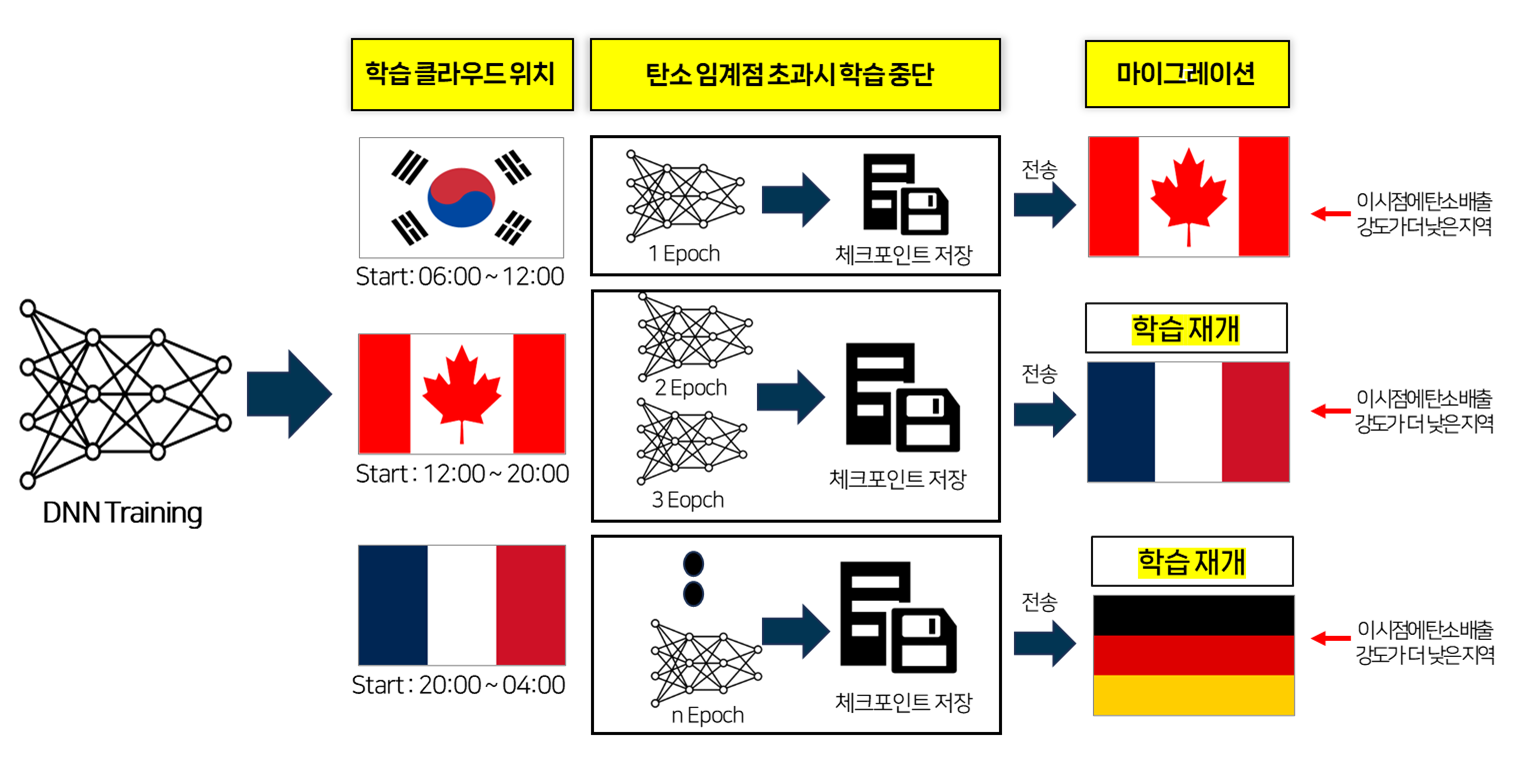
##### 그림. 2 분산된 클라우드에서 딥러닝 워크로드의 탄소 인지형 이동 기술
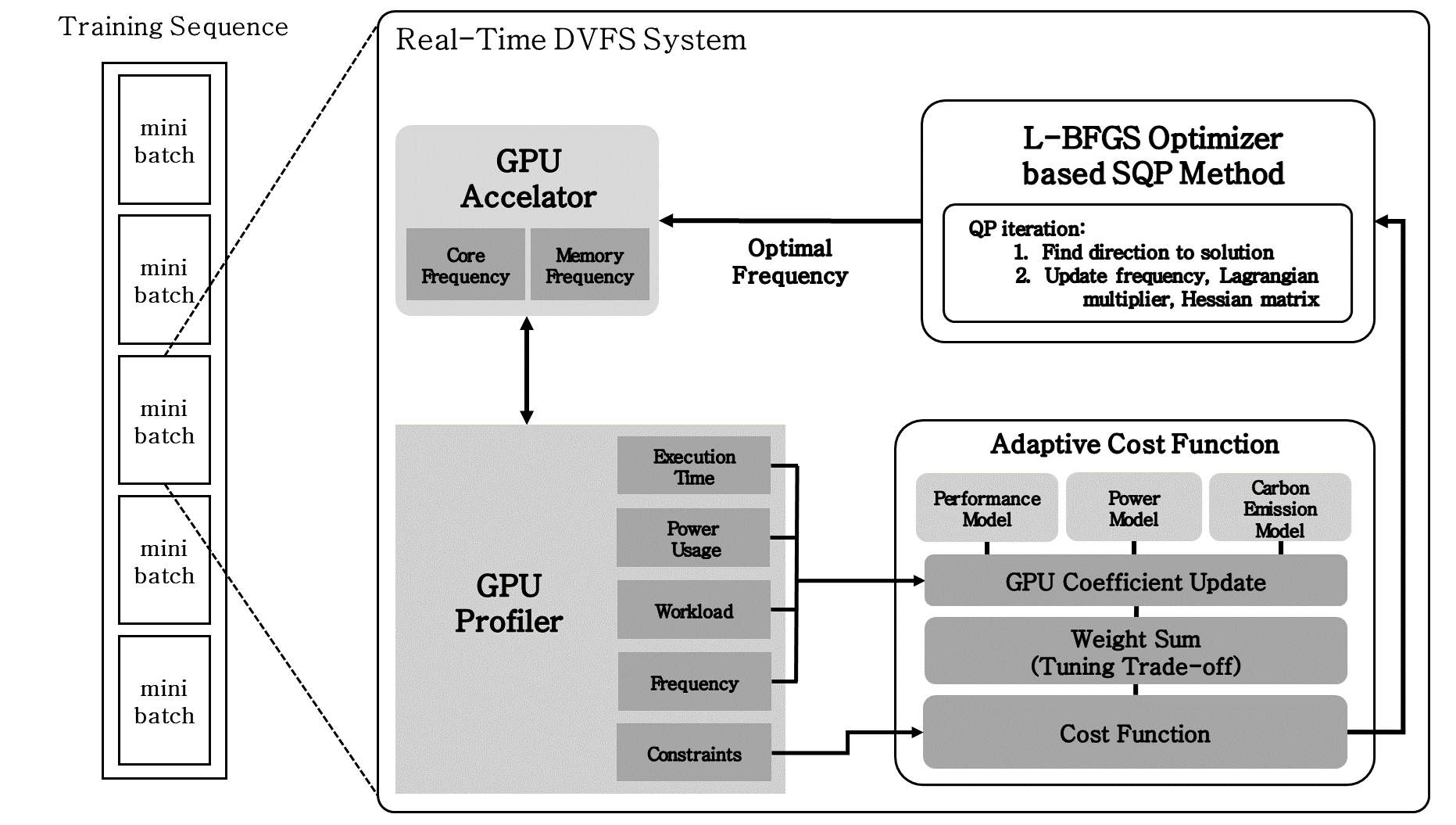
##### 그림. 3 전력 소비량 최소화를 위한 GPU 주파수 최적화 기술
그림. 2는 탄소를 고려한 안정적인 마이그레이션 방법에 대하여 나타낸다.
- 대한민국에 위치한 클라우드에서 06시에 딥러닝 학습을 시작한다.
- 반복 학습 진행 중, 캐나다의 탄소 배출 강도가 대한민국보다 낮아진 경우 클라우드에 체크포인트를 저장한다.
- 저장된 체크포인트를 사용하여 캐나다에 위치한 클라우드로 마이그레이션을 수행하여 학습을 재개한다. 이를 반복하여 탄소 인지 딥러닝 학습을 진행한다.
그림. 6은 관용 상태와 스케일링 상태의 전환에 따라 최적의 GPU 주파수를 탐색하고 적용하는 방법을 나타낸다.
- 관용 상태에서는 스케일링 상태에서 최적화된 GPU의 연산 속도로 미니 배치* 단위의 학습을 수행하며, 학습에서 발생하는 비용을 측정하기 위해 프로파일링을 병렬적으로 진행한다. *미니 배치 : 딥러닝에서 사용되는 학습 데이터의 일부분을 의미한다.
- 미니 배치 학습이 종료되었을 때, 현재 클라우드 위치의 탄소 강도가 임계점을 초과하는지 판별하여 관용 상태에서 스케일링 상태로 전환을 결정한다.
- 스케일링 상태에서는 GPU 최적 주파수 탐색 및 적용이 이루어진다.
- 학습 비용 예측 모델의 정확성을 향상시키기 위해, 프로파일된 실제 비용을 바탕으로 예측 모델의 GPU 효율 계수를 업데이트한다.
- 비선형 최적화 알고리즘을 통해 비용 함수의 비용을 최소화하는 GPU 최적 주파수를 도출한다.
- GPU 자원 관리 인터페이스를 활용하여 최적 주파수를 GPU에 적용하고, 스케일링 상태에서 관용 상태로 전환한다.
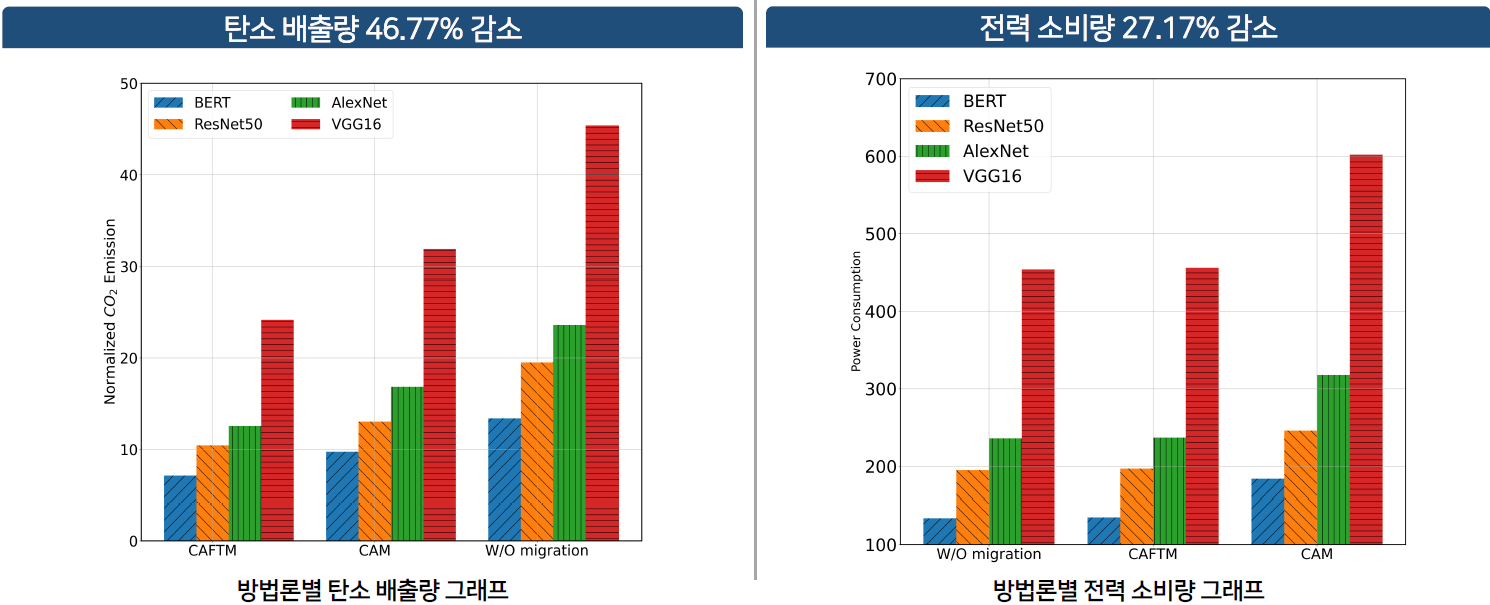
4. 결과
5. CITE
@INPROCEEDINGS{10643899,
author={Park, Jeonghyeon and Kim, Daero and Kim, Jiseon and Han, Jungkyu and Chun, Sejin},
booktitle={2024 IEEE 17th International Conference on Cloud Computing (CLOUD)},
title={Carbon-Aware and Fault-Tolerant Migration of Deep Learning Workloads in the Geo-Distributed Cloud},
year={2024},
}